BERT Embeddings
Categories:
This page explains the concept of embeddings in neural networks and illustrates the function of the BERT Embedding Layer.
Understanding Embeddings
The features, or inputs, to any machine learning model can generally be considered either continuous or categorical.
Continuous features represent numerical values. Below are a few examples of continuous features:
- The salary of an employee (e.g. 100,000).
- The number of times a user has watched a video (e.g. 10).
- The price of a house in dollars (e.g. 350,000).
Categorical features represent instances of a particular category. Categorical features have a finite set of possible values. Below are a few examples of categorical features:
- The job title of an employee (e.g. “Manager”)
- The genre of a movie (e.g. “Horror”)
- The breed of a dog (e.g. “Labrador Retriever”)
An Embedding is a trained numerical representation of a categorical feature. In practice, this means a list of floating point values that are learned during model training. The number of these values, also called the Embedding size, can vary from model to model.
For example, if an embedding of size 8 was used to represent movie genres, then each genre would map to a particular list of 8 floating point values, and these values would be learned during training like any other trainable weight in the neural network.
BERT Embeddings
To represent textual input data, BERT relies on 3 distinct types of embeddings: Token Embeddings, Position Embeddings, and Token Type Embeddings.
Token Embeddings
Before a string of text is passed to the BERT model, the BERT Tokenizer is used to convert the input from a string into a list of integer Token IDs, where each ID directly maps to a word or part of a word in the original string.
For example, the string "hello, world!" is converted by the Tokenizer into the following Token IDs:
101 7592 1010 2088 999 102
>>> import transformers
>>> tokenizer = transformers.TFBertTokenizer.from_pretrained("bert-base-uncased")
>>> tokens = tokenizer(["hello, world!"])
>>> print(tokens['input_ids'])
tf.Tensor([[ 101 7592 1010 2088 999 102]], shape=(1, 6), dtype=int64)
For each unique Token ID (i.e. for each of the 30,522 words and subwords in the BERT Tokenizer’s vocabulary), the BERT model contains an embedding that is trained to represent that specific token. The Embedding Layer within the model is responsible for mapping tokens to their corresponding embeddings.
The examples on this page use the TFBertModel class from the HuggingFace transformers library to load and invoke a TensorFlow BERT model with pretrained weights.
>>> # initialize a pretrained BERT model.
>>> model = transformers.TFBertModel.from_pretrained("bert-base-uncased")
The bert.embeddings attribute of the model object can be used to view and execute the embedding layer on its own. The weight attribute of the layer contains the Token Embeddings (i.e. the embeddings for each token in the BERT tokenizer’s vocabulary).
>>> embedding_layer = model.bert.embeddings
>>> print(embedding_layer.weight)
<tf.Variable 'tf_bert_model/bert/embeddings/word_embeddings/weight:0' shape=(30522, 768) dtype=float32, numpy=
array([[-0.01018257, -0.06154883, -0.02649689, ..., -0.01985357,
-0.03720997, -0.00975152],
[-0.01170495, -0.06002603, -0.03233192, ..., -0.01681456,
-0.04009988, -0.0106634 ],
[-0.01975381, -0.06273633, -0.03262176, ..., -0.01650258,
-0.04198876, -0.00323178],
...,
[-0.02176224, -0.0556396 , -0.01346345, ..., -0.00432698,
-0.0151355 , -0.02489496],
[-0.04617237, -0.05647721, -0.00192082, ..., 0.01568751,
-0.01387033, -0.00945213],
[ 0.00145601, -0.08208051, -0.01597912, ..., -0.00811687,
-0.04746607, 0.07527421]], dtype=float32)>
The embeddings are returned as a 30522 x 768 matrix, or 2-dimensional tensor:
- The first dimension of this tensor is the size of the BERT tokenizer’s vocabulary: 30,522
- The second dimension is the embedding size, which is also called the Hidden Size. This is the number of trainable weights for each token in the vocabulary. The original BERT model has a Hidden Size of 768, but other variations of BERT have been trained with smaller and larger values of the Hidden Size.
To view the embedding for a particular word, first tokenize it to convert the word into an integer ID, then look up the embedding in the matrix by using the ID as an index.
The code below prints the token embedding for the word "dog":
>>> print(tokenizer(['dog']))
{'input_ids': <tf.Tensor: shape=(1, 3), dtype=int64, numpy=array([[ 101, 3899, 102]])>}
>>> print(embedding_layer.weight[3899])
tf.Tensor(
[ -0.01493477 0.01244431 0.00912774 ... -0.04449853 -0.01931076
0.02335184 ], shape=(768,), dtype=float32)
Comparing Embeddings
Although it is not obvious from looking at them, the embeddings for each Token ID are not just random numbers. These values were learned when the BERT model was trained, which means that each embedding encodes the model’s understand of that particular token.
It is possible to see which words the BERT model considers most similar by comparing their corresponding token embeddings. As each embedding is a vector, or 1-dimensional tensor, Cosine Similarity can be used to measure how alike any two embeddings are.
Try entering a word below to see which other words in the vocabulary have the most similar token embeddings:
| Word | - | - | - | - | - | - |
|---|---|---|---|---|---|---|
| Cosine Similarity | - | - | - | - | - | - |
Note: To improve performance, these cosine similarity computations are done using a smaller variation of BERT with a Hidden Size of 128
Position Embeddings
In addition to the Token Embeddings described so far, BERT also relies on Position Embeddings. While Token Embeddings are used to represent each possible word or subword that can be provided to the model, Position Embeddings represent the position of each token in the input sequence.
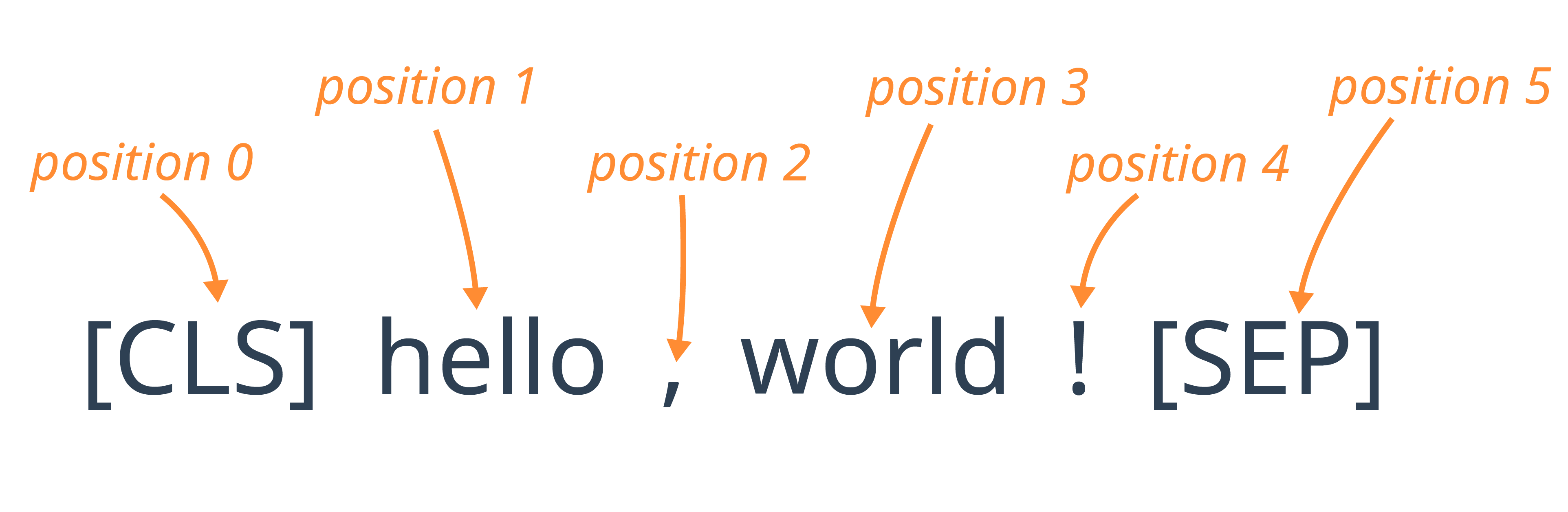
The position_embeddings attribute of the Embedding Layer is used to access the Position Embeddings:
>>> print(embedding_layer.position_embeddings)
<tf.Variable 'tf_bert_model/bert/embeddings/position_embeddings/embeddings:0' shape=(512, 768) dtype=float32, numpy=
array([[ 1.7505383e-02, -2.5631009e-02, -3.6641564e-02, ...,
3.3437202e-05, 6.8312453e-04, 1.5441139e-02],
[ 7.7580423e-03, 2.2613001e-03, -1.9444324e-02, ...,
2.8909724e-02, 2.9752752e-02, -5.3246655e-03],
[-1.1287465e-02, -1.9644140e-03, -1.1572698e-02, ...,
1.4907907e-02, 1.8740905e-02, -7.3139993e-03],
...,
[ 1.7417932e-02, 3.4902694e-03, -9.5621375e-03, ...,
2.9599327e-03, 4.3434653e-04, -2.6948910e-02],
[ 2.1686664e-02, -6.0216337e-03, 1.4735642e-02, ...,
-5.6118402e-03, -1.2589799e-02, -2.8084971e-02],
[ 2.6412839e-03, -2.3297865e-02, 5.4921862e-03, ...,
1.7536936e-02, 2.7549751e-02, -7.7655964e-02]], dtype=float32)>
While there are 30,522 different Token Embeddings, there are only 512 different Position Embeddings. This is because the largest input sequence accepted by the BERT model is 512 tokens long.
Token Type Embeddings
The final type of embedding used by BERT is the Token Type Embedding, also called the Segment Embedding in the original BERT Paper. One of the tasks that BERT was originally trained to solve was Next Sentence Prediction. That is, given two sentences A and B, BERT was trained to determine whether B logically follows A.
The token_type_embeddings attribute of the Embedding Layer object is used to access the Token Type Embeddings:
>>> print(embedding_layer.token_type_embeddings)
>>> <tf.Variable 'tf_bert_model/bert/embeddings/token_type_embeddings/embeddings:0' shape=(2, 768) dtype=float32, numpy=
array([[ 0.00043164, 0.01098826, 0.00370439, ..., -0.00661185,
-0.00336983, -0.00864201],
[ 0.00111319, -0.00299169, -0.00317028, ..., 0.00474542,
-0.0052443 , -0.01121742]], dtype=float32)>
There are only two different Token Type Embeddings: one used to represent tokens in sentence A, and one used to represent tokens in sentence B.
BERT Embedding Layer
Given a list of Token IDs, the BERT Embedding Layer is reponsible for computing a final embedding for each input token by combining the three type of embeddings discussed so far, namely, Token Embeddings, Position Embeddings, and Token Type Embeddings.
The final embedding for each token is computed by summing the embeddings for its specific token ID, position, and token type, and then applying normalization on the sums. The illustration below shows how the BERT Embedding Layer computes the embedding for the string "hello, world!"
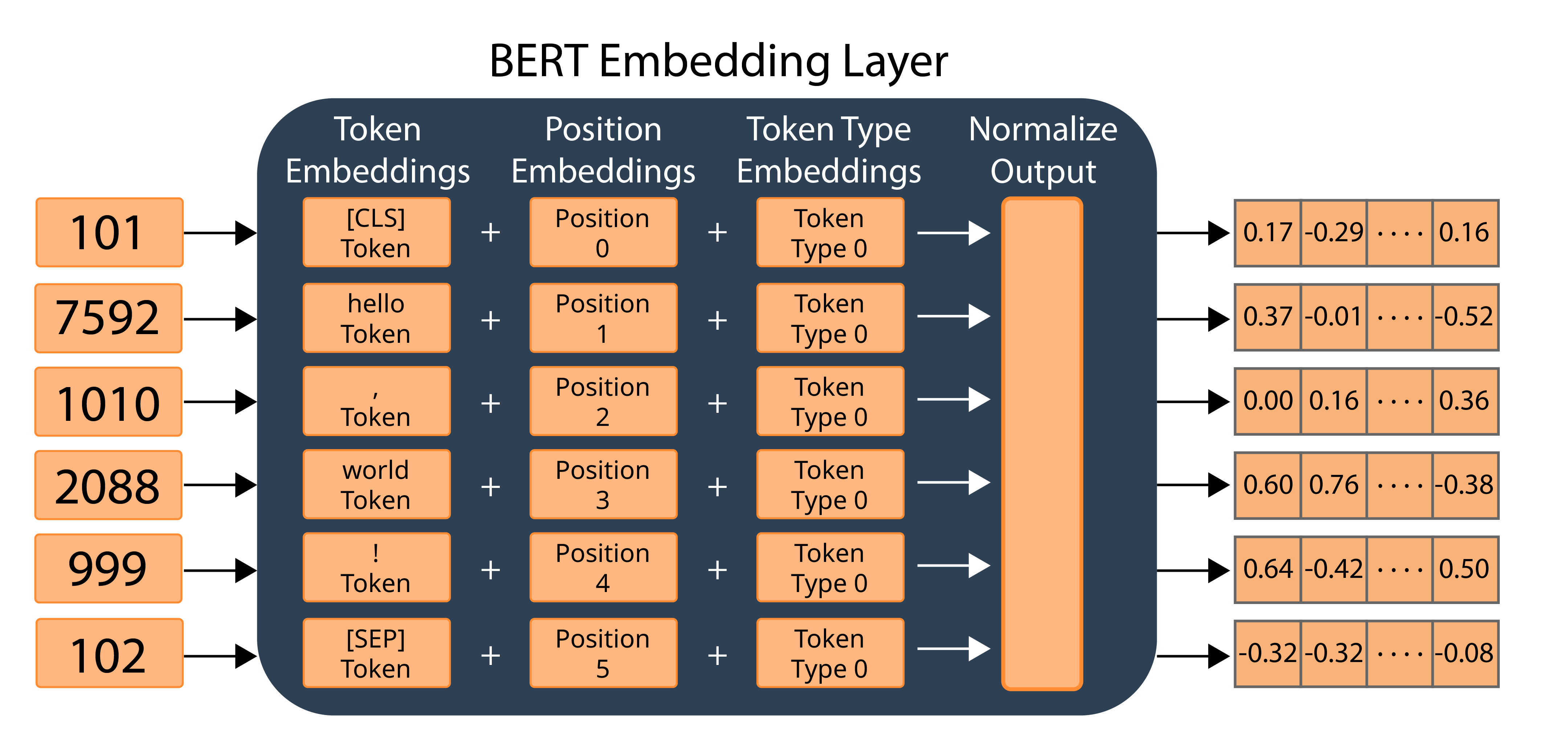
To demonstrate this, compute the final embeddings by calling the BERT Embedding Layer as a function:
>>> tokens = tokenizer(['hello, world!'])
>>> final_embeddings = embedding_layer(tokens['input_ids'])
>>> print(final_embeddings)
<tf.Tensor: shape=(1, 6, 768), dtype=float32, numpy=
array([[[ 1.68550596e-01, -2.85767317e-01, -3.26125681e-01, ...,
-2.75705811e-02, 3.82532738e-02, 1.63995296e-01],
[ 3.73858035e-01, -1.55751705e-02, -2.45609313e-01, ...,
-3.16567719e-02, 5.51443100e-01, -5.24057627e-01],
[ 4.67032194e-04, 1.62245125e-01, -6.44427389e-02, ...,
4.94433701e-01, 6.94125414e-01, 3.62857282e-01],
[ 6.03888452e-01, 7.59982109e-01, 3.16263884e-02, ...,
-1.92956910e-01, 2.17443466e-01, -3.83179694e-01],
[ 6.42427564e-01, -4.22579020e-01, -4.06281352e-01, ...,
6.26115143e-01, 5.61072588e-01, 5.05879104e-01],
[-3.25073361e-01, -3.18785489e-01, -1.16317727e-01, ...,
-3.96022975e-01, 4.11199152e-01, -7.75520504e-02]]],
dtype=float32)>
The three dimensions in the output represent the batch size, the number of input tokens, and the hidden size, respectively.
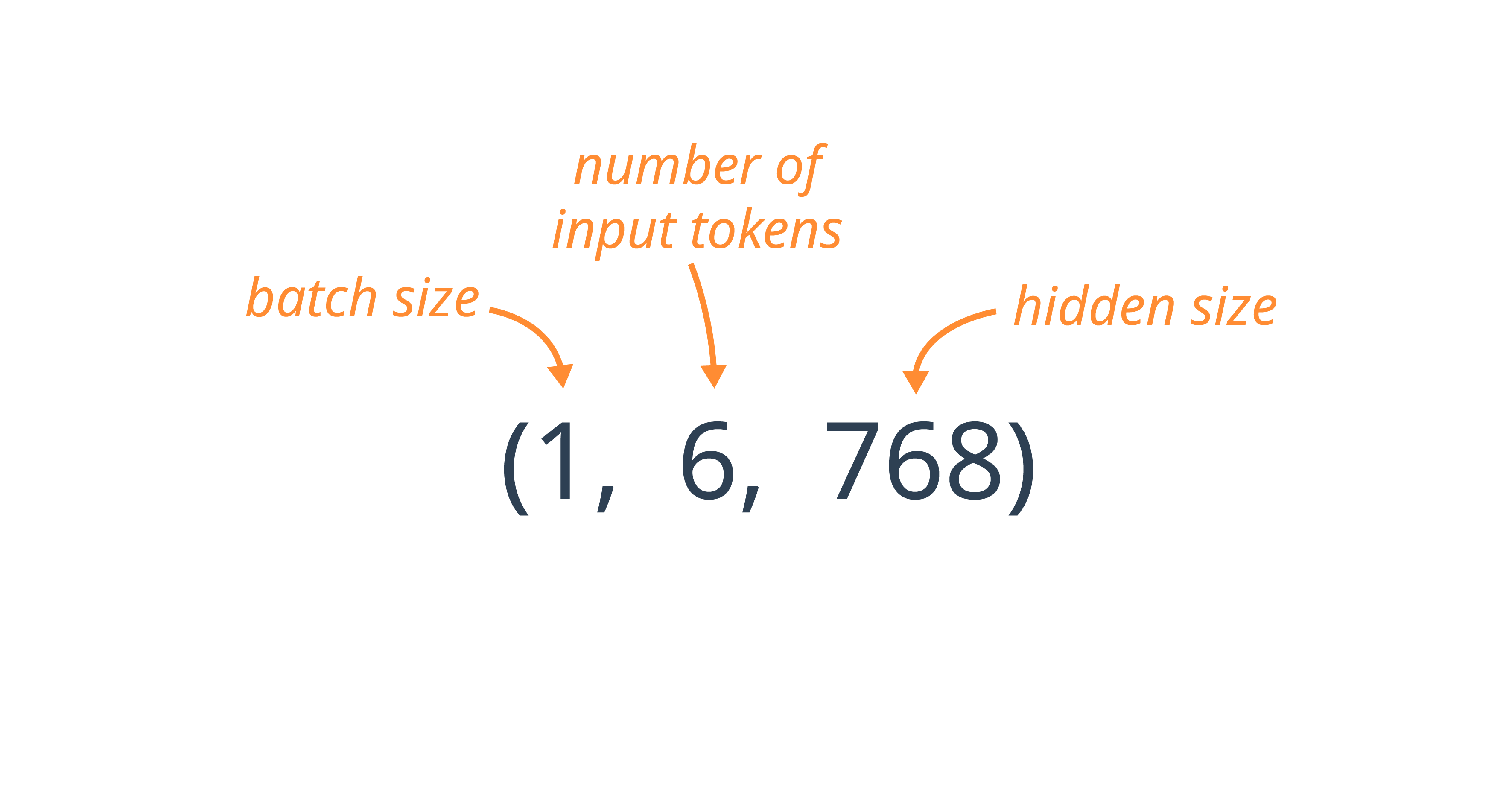
Consider the final embedding for the input string "world" in the example above, which can be viewed at index [0, 4] in the Embedding Layer output (i.e. the 3rd element in the 1st batch).
>>> print(final_embeddings[0, 3])
tf.Tensor(
[ 6.03888452e-01 7.59982109e-01 3.16263884e-02 ... -1.92956910e-01
2.17443466e-01 -3.83179694e-01], shape=(768,), dtype=float32)
This final embedding for "world" in this example is the normalized sum of the Token Embedding for token 2088, the Position Embedding for position 3, and the Token Type Embedding for token type 0.
>>> # Sum the three embedding types
>>> embedding_sum = (
... embedding_layer.weight[2088] +
... embedding_layer.position_embeddings[3] +
... embedding_layer.token_type_embeddings[0]
... )
>>> # Apply normalization. embedding_sum is
>>> # reshaped to include the first two dimensions
>>> # required by the normalization operation.
>>> final_embedding = embedding_layer.LayerNorm(
... tf.reshape(embedding_sum, (1, 1, 768))
... )
>>> print(final_embedding)
tf.Tensor(
[[[ 6.03888452e-01 7.59982109e-01 3.16263884e-02 ... -1.92956910e-01
2.17443466e-01 -3.83179694e-01]]], shape=(1, 1, 768), dtype=float32)
Summary
This page covered the BERT Embedding Layer, the first trainable layer in the BERT neural network. Next, we explore the BERT encoder, which relies on the transformer neural network architecture to further refine the embeddings produced by the BERT Embedding Layer.